跨平台的浏览器自动化工具Playwright简析
从以下几个方面分析下Puppeteer的衍生项目Playwirght:
- 基本介绍与使用示例
- 云原生:BrowserContext的隔离与增强
- 跨平台:不同平台通用的Client与Server实现
- 多选择器:内置与自定义选择器引擎
之前使用并介绍过一个不错的浏览器自动化测试工具Puppeteer,具有API易于使用且有关Chrome浏览器自动化功能强大的特点。
在最近出现了另一个浏览器自动化项目Playwright,该项目支持多种内核(chromium, webkit, firefox)的浏览器自动化操作,弥补了Puppeteer本身无法跨平台的不足(虽存在puppeteer-firefox),API风格与Puppeteer保持一致,一定程度上算是Puppeteer的衍生品。
下面来尝尝鲜,看看它与puppeteer具体有什么不同,简要分析其原理与设计。
基本介绍
为何会产生这个项目,与Puppeteer有什么关系,在它的README的faq中有详细介绍。
简要的说就是:
- 弥补了Puppeteer的平台局限性,为所有热门渲染引擎提供类似的功能
- 借鉴了Puppeteer测试友好的API设计(如click会等到元素可用并默认可见)
- 目标云原生(cloud-native),隔离了BrowserContext,使其不仅是一个页面而将它当做一个库来操作,可以在本地创建也可以作为服务提供
- 这些改动会对Puppteer的API产生Breaking change,因此决定重启一个干净的项目
其次Playwright完全采用TypeScript编写,利用类型优势的同时也便于在实现跨平台时进行统一的核心组件结构设计。需要使用Node 10或更高版本的环境才可运行。
本文所用Playwright版本为0.11.1
目前Playwright的版本内容还处于不稳定的状态,下面展示的很多内容在未来可能都会发生改变
示例分析
从官方文档中截图操作的示例来看下两种工具的API使用
Puppeteer Page screenshot Example:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
Playwright Page screenshot Example:
const playwright = require('playwright');
(async () => {
for (const browserType of ['chromium', 'firefox', 'webkit']) {
const browser = await playwright[browserType].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('http://whatsmyuseragent.org/');
await page.screenshot({ path: `example-${browserType}.png` });
await browser.close();
}
})();
可以注意到有一处修改和一处新增:
- 修改:首先在客户端启动时,由于跨平台特性需要在创建时使用指定平台的类
playwright[browserType] - 新增:Playwright的示例在创建新页面前需要先创建一个上下文,然后在context上创建页面
熟悉Puppeteer的同学也许知道,browser.newPage()实际上也是执行内部默认BrowserContext实例上的newPage方法,至于BrowserContext的所处位置可以参考下面的Puppeteer架构图:
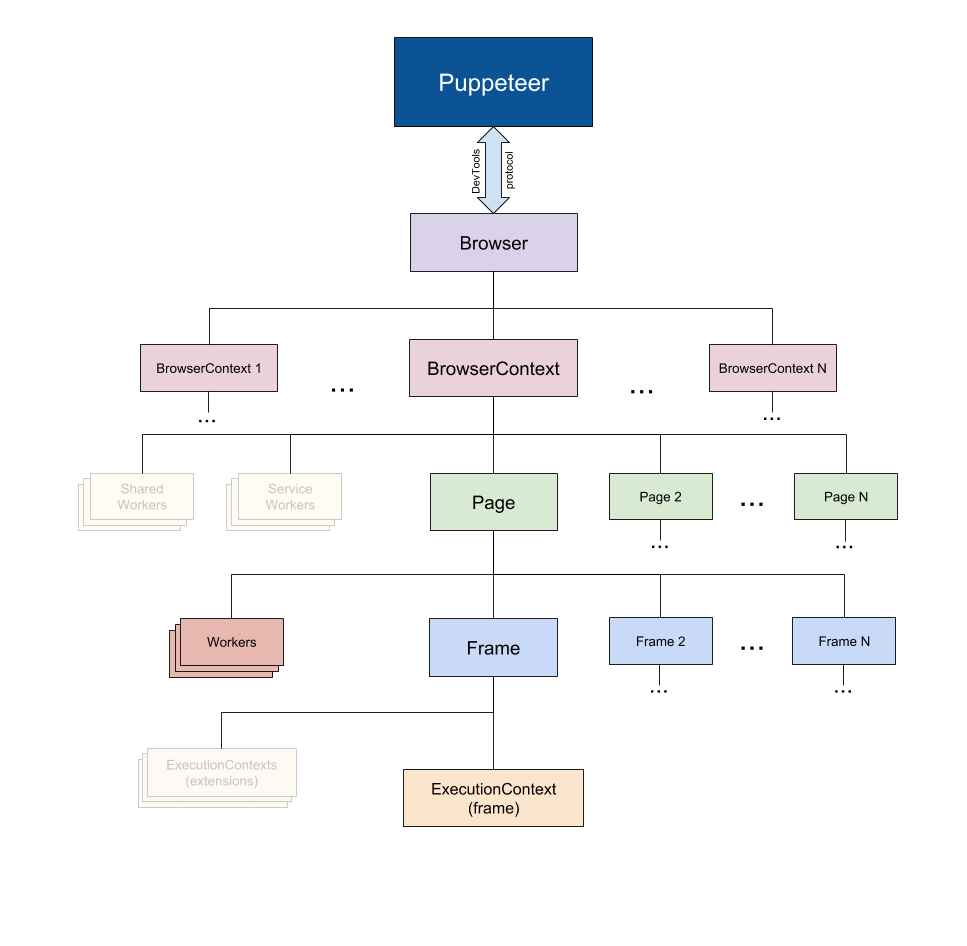
在BrowserContext实例中管理会话对象与页面对象。
实际上在Playwright中写成browser.newPage()也是可以的,但它的内部执行与Puppeteer不同:Puppeteer会在默认的context上创建页面,而Playwright会重新创建新的context并创建页面,具体过程会在之后看到。至于Playwright为什么在示例中通过这种显式的创建新的context方法,可能是为了故意体现这个特点。
在Playwright中,Browser实例的默认context仅会当监听到targetCreated事件时不存在指定context时才会用到:
export class CRBrowser extends platform.EventEmitter implements Browser {
readonly _defaultContext: CRBrowserContext;
async _targetCreated() {
...
const context = (browserContextId && this._contexts.has(browserContextId)) ? this._contexts.get(browserContextId)! : this._defaultContext;
...
}
}
隔离与增强BrowserContext - 云原生
对开发者目标云原生的描述不做说明(因为不怎么懂),仅关注下它所提到的对BrowserContext做出的改变,下面从一个例子开始。
创建一个页面
来看看在两个框架在通过Browser实例创建页面时的内部执行流程有什么不同:
Puppeteer中:
-
利用默认context创建页面
class Browser extends EventEmitter { async newPage() { return this._defaultContext.newPage(); } -
执行绑定浏览器实例的创建页面方法
class BrowserContext extends EventEmitter { newPage() { return this._browser._createPageInContext(this._id); } } -
向远程浏览器发送createTarget消息
class Browser extends EventEmitter { async _createPageInContext(contextId) { const {targetId} = await this._connection.send('Target.createTarget', {url: 'about:blank', browserContextId: contextId || undefined}); const target = await this._targets.get(targetId); const page = await target.page(); return page; } }
在Playwright中:
-
调用独立方法创建页面
export class CRBrowser extends platform.EventEmitter implements Browser { async newPage(options?: BrowserContextOptions): Promise<Page> { return createPageInNewContext(this, options); } } -
创建一个新的context来创建页面
// browser.ts /* 第二步 */ export async function createPageInNewContext(browser: Browser, options?: BrowserContextOptions): Promise<Page> { const context = await browser.newContext(options); const page = await context.newPage(); page._ownedContext = context; return page; } -
向远程浏览器发送createTarget消息
export class CRBrowserContext extends platform.EventEmitter implements BrowserContext { async newPage(): Promise<Page> { const { targetId } = await this._browser._client.send('Target.createTarget', { url: 'about:blank', browserContextId: this._browserContextId || undefined }); const target = this._browser._targets.get(targetId)!; const page = await target.page(); return page!; } }
可以看到主要有如下变动,在Playwright中:
- 将创建页面操作从Browser中分离出来,移至BrowserContext中
- 对于每个新页面会新建一个context,而不是像Puppeteer使用默认的context
BrowserContext的能力扩展
从项目的多个PR中可以看出,开发者将将下游的Page一些属性和能力移到了BrowserContext中,并且实现了其他功能,如:
- Page提升至BrowserContext的能力
- Cookie管理#82
- 认证配置#1267:Page.authenticate => BrowserContext.setHTTPCredentials
- 离线模式#1229: Page.setOfflineMode => BrowserContext.setOffline
- 能力增强
- 设置默认超时#992
- 额外的HTTP Header配置#1116: BrowserContext.setDefaultHTTPHeaders
- Document中的脚本注入#1136: BrowserContext.evaluateOnNewDocument
- 匹配URL的Route处理#1295: BrowserContext.route()
- 其他
- Browser中复用BrowserContext#201
各平台的Client与Server实现 - 跨平台
为了实现跨平台,Playwright设计了一些通用的全局组件与实现统一标准的各平台组件来实现Client,供Node端使用,同时也提供了针对每种平台的用于远程调试的Server,通过Connection与Client通信,收发消息执行对应的自动化操作。
Client组件
三种平台均实现了下面这些Client核心组件
- 客户端与页面: :Browser, BrowserContext, Page
- 连接与会话:Connection, Session
- 执行上下文与注入脚本:ExecutionContext
- 网络管理与请求:NetworkManager, InterceptableRequest
- 用户输入:RawKeyboardImpl, RawMouseImpl
通过分析源码整理出这些类之间的关系大致如下图所示:
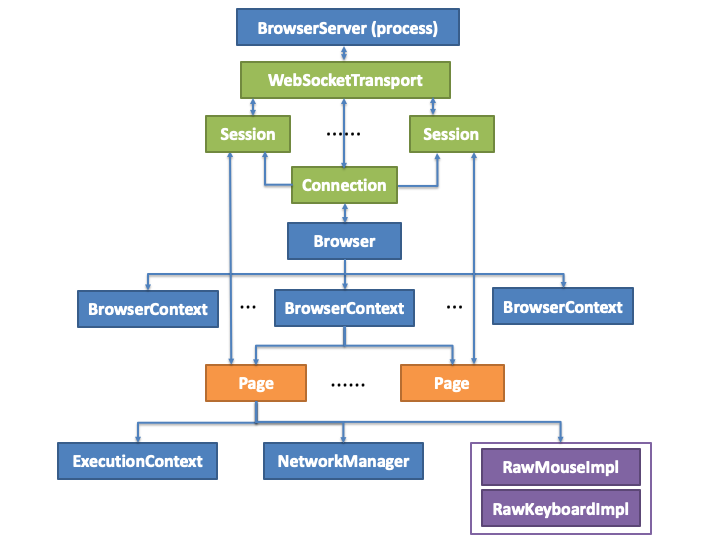
可以看出这个结构与Puppeteer非常相似,在多个平台的实现中使用共同的组件与架构来实现跨平台的特性。
能力差异
目前chromium端的能力是最丰富的,这源于Puppeteer的基础和CDP提供的细粒度操作。不同平台的client相关文件对比如下图:
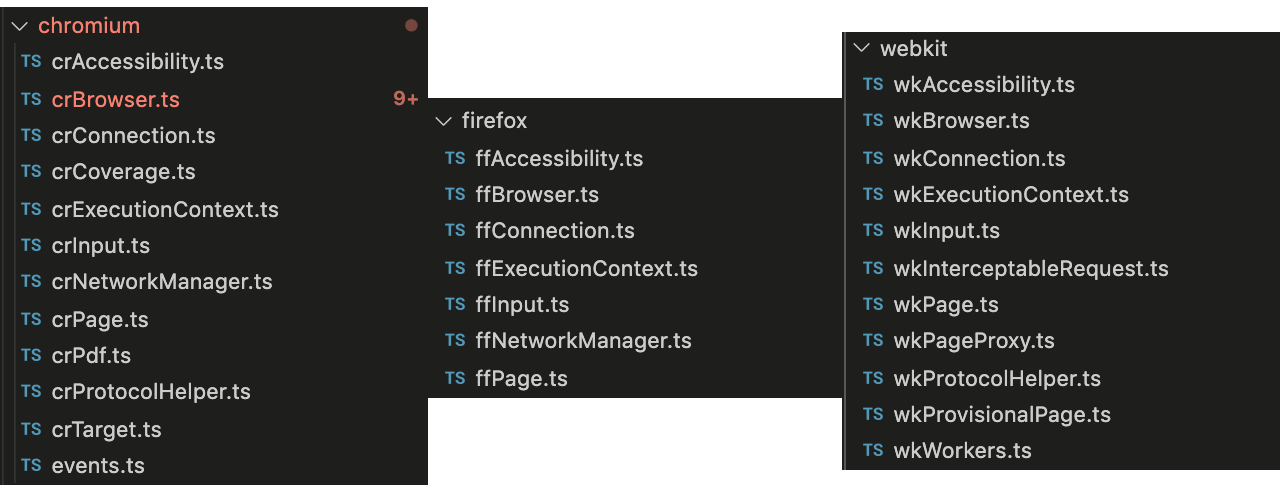
所有平台的Browser实例通用API如下:
- event: ‘disconnected’
- browser.close()
- browser.contexts()
- browser.isConnected()
- browser.newContext([options])
- browser.newPage([options])
其中ChromiumBrowser独有的能力有Tracing, ServiceWorker等。
Server组件
除了的可以处理事件、执行设置与操作常用对象能力的客户端外,还需要启动一个浏览器实例和建立一个用于信息交换的通道。
即前述框图中的BrowserServer与Transport。
Server中包含启动浏览器实例的子进程、WS端口信息与数据通道实例。以chromium server为例:
// src/server/chromium.ts
export class Chromium implements BrowserType {
async launch() {
// 使用local模式启动server
const { browserServer, transport } = await this._launchServer(options, 'local');
const browser = await CRBrowser.connect(transport!, options);
browser.close = () => browserServer.close();
return browser;
}
private async _launchServer() {
let browserServer: BrowserServer | undefined = undefined;
/* 1. 启动Node子进程,运行浏览器实例 */
const { launchedProcess, gracefullyClose } = await launchProcess({ ... })
/* 2. 准备数据通道 */
let transport: ConnectionTransport | undefined;
let browserWSEndpoint: string | null;
if (launchType === 'server') {
...
// server模式会获取子进程暴露出的ws端口
const match = await waitForLine(launchedProcess, launchedProcess.stderr, /^DevTools listening on (ws:\/\/.*)$/, timeout, timeoutError);
browserWSEndpoint = match[1];
} else {
// local模式会利用子进程的标准端口创建数据通道
transport = new PipeTransport(launchedProcess.stdio[3] as NodeJS.WritableStream, launchedProcess.stdio[4] as NodeJS.ReadableStream);
browserWSEndpoint = null;
}
browserServer = new BrowserServer(launchedProcess, gracefullyClose, browserWSEndpoint);
/* 3. 返回server与transport通道,后续在browser上绑定server的close方法,使用transport通道创建Connection对象来管理所有Session会话 */
return { browserServer, transport };
}
}
firefox和webkit的流程与chromium的launch流程类似,在创建transport与browserServer时的参数与内容略有不同。
选择器引擎 - 多选择器
选择器可以用在获取元素(ElementHandle)与交互事件等场合,在Puppeteer中仅支持默认的CSS选择器:
page.$('div > span#text') // => ElementHandle
page.$$('.user-table') // => Array<ElementHandle>
page.click('#button')
Playwright则通过引入多种Selector引擎实现了多种可用选择器,包含CSS、XPath、text、id等,并且可以自定义选择器引擎。
由于同时支持多种选择器,因此其使用的选择器语句也进行了一定设计。
选择语句
由子句与**>>分隔符**组成。如子句1 >> 子句2 >> 子句3,当存在多个子句时,每个子句的源为前一子句的选择结果。
子句的格式为引擎=主体。如engine=body。若body中需要使用>>的话需要字符串类型处理,避免被分割成两个子句,如text="hello >> world"。
例子:
css=div >> css=.form > span >> css=input[attr=name] 等价于
document
.querySelector('div')
.querySelector('.form > span')
.querySelector('input[attr=name]')
格式转换:当格式错误或没有设置格式时,会根据内容尝试转换成正确格式:
- 以
//开头的选择器主体会被认为是xpath=selector - 以
"开头的选择器主体会被认为是text=selector - 其他情况会被人为是
css=selector
内置Selector引擎
-
CSS
-
XPath
-
text
找到包含传入文本的text node所在的元素。大小写不敏感,
text=Login会匹配到<button>loGIN </button> -
id
根据元素的attribute属性来选择。
data-test-id=foo等价于querySelector('*[data-test-id=foo]')
选择器的实现与内部使用
选择器引擎类
选择器引擎是可以自定义,一般为如下结构:
// 一个可以注入到选择器引擎实例中的函数
const createTagNameEngine = () => ({
// 创建一个从根元素到目标元素的选择器(利用选择器选择元素的反向操作)
create(root, target) {
return root.querySelector(target.tagName) === target ? target.tagName : undefined;
},
// 返回根元素子树上的第一个匹配元素
query(root, selector) {
return root.querySelector(selector);
},
// 返回根元素子树上的所有匹配元素
queryAll(root, selector) {
return Array.from(root.querySelectorAll(selector));
}
});
所有选择器引擎的本质都是解析特定的选择器语法,转换成querySelector或evaluate语句。
整合与打包
内置选择器引擎与配置文件在src/injected目录中,所有文件被整合进了injected.ts中。
在Injected类中会载入所有预置的选择器引擎及自定义的引擎:
// src/injected/injected.ts
class Injected {
readonly engines: Map<string, SelectorEngine>;
// 加载所有内置与自定义选择器引擎
constructor(customEngines: { name: string, engine: SelectorEngine}[]) {
this.engines = new Map();
this.engines.set('css', CSSEngine);
this.engines.set('xpath', XPathEngine);
this.engines.set('text', TextEngine);
this.engines.set('id', createAttributeEngine('id'));
...
for (const {name, engine} of customEngines)
this.engines.set(name, engine);
}
提供与dom API命名一致的选择器顶层API:
class Injected {
// 实现顶层的元素选择方法,递归调用
querySelector(selector: string, root: Node): Element | undefined {
const parsed = this._parseSelector(selector);
if (!(root as any)['querySelector'])
throw new Error('Node is not queryable.');
// 递归查找元素
return this._querySelectorRecursively(root as SelectorRoot, parsed, 0);
}
}
在API内部调用当前引擎的query等方法执行元素选择:
class Injected {
private _querySelectorRecursively(root: SelectorRoot, parsed: ParsedSelector, index: number): Element | undefined {
const current = parsed[index];
root = (root as Element).shadowRoot || root;
// 在根元素上使用当前引擎内置的query与queryAll方法查找元素
if (index === parsed.length - 1)
return current.engine.query(root, current.selector);
const all = current.engine.queryAll(root, current.selector);
for (const next of all) {
const result = this._querySelectorRecursively(next, parsed, index + 1);
if (result)
return result;
}
}
}
这个类会在playwright构建时被webpack单独打包成一个inline module并在dom.ts中引入。
当在Node中调用需要元素选择的方法时,该模块会被注入到浏览器的执行上下文中,在Document上执行元素选择,返回经过处理的ElementHandle Promise。
// src/injected/injected.webpack.config.js
module.exports = {
...
output: {
filename: 'injectedSource.js',
path: path.resolve(__dirname, '../../lib/injected/packed')
},
plugins: [
new InlineSource(path.join(__dirname, '..', 'generated', 'injectedSource.ts')),
]
}
// src/dom.ts
import * as injectedSource from './generated/injectedSource';
export class FrameExecutionContext extends js.ExecutionContext {
// 注入所有选择器引擎代码并创建引擎实例
_injected(): Promise<js.JSHandle> {
const selectors = Selectors._instance();
if (!this._injectedPromise) {
const custom: string[] = [];
for (const [name, source] of selectors._engines)
custom.push(`{ name: '${name}', engine: (${source}) }`);
const source = `
new (${injectedSource.source})([
${custom.join(',\n')}
])
`;
this._injectedPromise = this.evaluateHandle(source);
this._injectedGeneration = selectors._generation;
}
return this._injectedPromise;
}
// $()方法用于选择单个元素-ElementHandle
async _$(selector: string, scope?: ElementHandle): Promise<ElementHandle<Element> | null> {
const handle = await this.evaluateHandle(
// 调用injected执行元素选择
(injected: Injected, selector: string, scope?: Node) => injected.querySelector(selector, scope || document),
await this._injected(), selector, scope
);
if (!handle.asElement())
await handle.dispose();
return handle.asElement() as ElementHandle<Element>;
}
}
基本上选择器的处理流程就如上所述了。
其他
*-core版本
许多人在初次使用Puppeteer时都会遇到下载chromium速度过慢,导致安装失败的问题。为了解决这个问题,官方在之后提供了puppeteer-core库,可以指定本地的浏览器binary文件而无需再次下载。
Playwright目前仍处于早期开发阶段,已经有了实现这种方案的计划并进行了初步实施,但目前还没有稳定版的chrome可以支持所有的Playwright特性,并且针对firefox和webkit的改动也没有完全同步,可以说是稍安勿躁了。具体可以参考这个issue
社区实践
官方文档中提供了多种类型的社区实践与代码示例:
- 使用Playwright的用户
- 工具
- 集成测试框架
- 代码示例
- 原文作者:yrq110
- 原文链接:http://yrq110.me/post/front-end/dive-into-playwright/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。